Python asyncio
FTRL算法
在线学习
传统的离线批量算法无法有效地处理超大规模的数据集和在线数据流。 Online Learning不需要所有数据,可以以流式的方式处理任意数量的样本,是工业界做在线 CTR 预估时的常用算法。
其实现方式大致可分为两种:
- 在线凸优化(Online learning convex optimization)
- FOBOS
- RDA
- FTRL
- 在线贝叶斯(Online learning Bayesian)
- AdPredictor
- PBODL
FTRL
FTRL(Follow The Regularized Leader)算法就是 Online Learning 凸优化的一种。 Google H. Brendan McMahan 先后三年时间(2010年-2013年)从理论研究到实际工程化实现的 FTRL 算法:
- 2010年: Adaptive Bound Optimization for Online Convex Optimization
理论性paper,但未显式地支持正则化项迭代 - 2011年: A Unified View of Regularized Dual Averaging and Mirror Descent with Implicit Updates
证明 regret bound 以及引入通用的正则化项 - 2011年: Follow-the-Regularized-Leader and Mirror Descent: Equivalence Theorems and L1 Regularization
揭示 OGD, FOBOS, RDA 等算法与 FTRL 关系 - 2013年: Ad Click Prediction: a View from the Trenches
给出了工程性实现,并且附带了详细的伪代码,开始被大规模应用
FTRL 在处理诸如逻辑回归之类的带非光滑正则化项(例如1范数,做模型复杂度控制和稀疏化)的凸优化问题上性能非常出色。
逻辑回归
逻辑回归的目标函数可归纳为:
为逻辑函数,是正则系数,是正则函数
而逻辑回归的优化方法,传统的批量方法每次迭代都对存量训练数据集进行计算:
- 梯度下降法
- 批量梯度下降(BGD)
- 随机梯度下降(SGD)
- 小批量梯度下降(MBGD)
- 还有很对基于梯度下降的新的优化方法。因为目前深度学习火热,产生了很多对梯度下降改进的优化方法
- 牛顿法、拟牛顿法(L-BFGS)。因为用到了二阶导数,所以一般对于光滑的正则约束项(如L2)效果好点。
梯度下降法优点是精度和收敛效果不错,但是批量梯度下降(BGD)用全量数据进行计算,计算代价太大,没法应用于数据流做在线学习。随机梯度下降(SGD)和小批量梯度下降(MBGD)倒是可以只用部分数据进行计算。
在线学习算法
典型的线性函数随机梯度下降(SGD)参数更新的公式为:。如果每次不是取随机值,而是用从数据流中获得的新数据计算梯度,就能完成在线学习的过程。
姑且称为在线梯度下降。 同样,线性函数小批量梯度下降(MBGD)参数更新的公式为:。如果每次不是随机找小批量,而是将从数据流中获得的新数据包含到小批量中计算梯度,也能完成在线学习的过程。
可以称为在线小批量梯度下降。
牛顿法、拟牛顿法算法实现少,巨耗内存。目前主流稳定的只有 SciPy 基于 Fortune 的实现和 SparkML 的实现,很难用到在线系统中。
在线梯度下降
梯度下降类的方法在进行在线学习是有两点不足:
- 简单的在线梯度下降很难产生真正稀疏的解,稀疏性在机器学习中是很重要的事情,尤其做工程应用,稀疏的特征会大大减少 inference 时的内存和复杂度。
- 对于不可微点的迭代会存在一些问题。猜想是由于流式的使用新的输入数据,而新数据的也许是一直变化的,会导致在边界点计算出现问题。
在线 CTR 预估时的特征一般非常之多,因此我们希望得到更加稀疏的模型,这不仅仅起到了特征选择的作用,也降低了预测计算的复杂度。在实际使用 LR 的时候都会使用 L1 或者 L2 正则,避免模型过拟合。 在 BGD 算法下,L1 正则化通常能得到更加稀疏的模型。可是在 SGD 算法下,特别是在线学习的过程中,参数并不是沿着全局梯度下降,而是沿着某个样本的梯度进行下降,这样即使是 L1 正则也不一定能得到稀疏解。 因此在后面的优化算法中,稀疏性是一个主要追求的目标。
算法优化
-
添加 L1 正则项
如之前提到的,在线学习的过程中参数并不是沿着全局梯度下降,而是沿着某个样本的梯度进行下降,L1 正则不一定会得到稀疏解。另外如果是自己实现的梯度下降算法,需要针对 float 数据类型做简单的阈值截断,牵涉到浮点数精度问题,否则很难能到 0 解。
-
暴力截断
上面已经提到为了避免浮点数精度的问题需要做一些截断,当然其目的是为了很小的浮点数相加为0,是基于计算的考虑。沿着这个思路,很容易就能想到基于模型的考虑,也能做截断,这是最直观没技术含量的思路,设定一个阈值,做截断来保证稀疏。每在线训练N个数据截断一次。
-
在 L1 正则的基础上做截断
很明显,简单截断的方法可以增加结果的稀疏性,但是会影响结果的精度。权重小的特征,可能是确实是无用特征,但也可能是在训练刚开始的阶段初始值本来很小、或者训练数据中包含该特征的样本数本来就很少。做为改进,很容易想到可以在添加了在 L1 正则的基础上做截断。
-
FOBOS
前向后向切分(FOBOS,Forward Backward Splitting)是 John Duchi 和 Yoran Singer 提出的。在该算法中,权重的更新分成两个步骤:
第一个步骤实际上是一个标准的梯度下降(SGD),其中,为当前梯度,第二个步骤是对第一个步骤的结果进行局部调整。写成一个公式那就是:
求偏导,得到权重更新的公式:
从上面的公式可以看出,更新后的 不仅和 有关,还和 有关,这也就是“前向后向切分”这个名称的由来。
在 L1 正则化下,FOBOS 的特征权重的各个维度的更新公式是:
其中是特征权重的某一维度,可以对 的每一个维度进行单独求解。
See the Pen FOBOS by Halo Pan (@Halo9Pan) on CodePen.
上面是一个一维的图,可以看出随着迭代次数的增加,会趋于稳定,但同时也能发现,取值对的影响。直观理解,因为是正则化系数,如果值太小,正则惩罚的力度太小,迭代更趋向于去拟合值。此处简化和取值一样,并且为固定值,但实际上可以为基于的单调函数。
-
RDA
RDA(Regularized Dual Averaging Algorithm)叫做正则对偶平均算法,特征权重的更新策略是:
,包括了之前所有梯度的平均值; 为正则项,为正则系数; 是一个严格凸函数,是一个非负递增序列
在 L1 正则化下,选取。那么 RDA 算法就改写为:
求偏导,得到更新公式:
-
FTRL
FTRL 算法综合考虑了 FOBOS 和 RDA 对于梯度和正则项的优势和不足,其特征权重的更新公式是:
其中。 在 L1 正则化下,算法就改写为:
求偏导,得到更新公式:
在 SGD, FOBOS, RDA 的算法里面使用的是一个全局的学习率 ,意味着学习率是一个正数并且逐渐递减,对每一个维度都是一样的。 而在 FTRL 算法里面,每个维度的学习率是不一样的。 FTRL 考虑了训练样本本身在不同特征上分布的不均匀性,如果某一个维度特征的训练样本很少,每一个样本都很珍贵,那么该特征维度对应的训练速率可以独自保持比较大的值,每来一个包含该特征的样本,就可以在该样本的梯度上前进一大步,而不需要与其他特征维度的前进步调强行保持一致。在 FTRL 中,维度的学习率是这样定义的:
定义, 所以
其中为学习率,为学习率的平滑系数,为 L1 正则系数,为 L2 正则系数。
工程实现
-
伪代码
伪代码在公式表达的基础上做了一些变换和实现上的trick,可以在实际数据集上并行加速:
-
Predict
因为添加了 L1 正则,训练结果 很稀疏
-
Training
-
在线丢弃训练数据中很少出现的特征
但是对于在线训练,对全数据进行处理查看哪些特征出现地很少、或者哪些特征无用,是代价很大的事情,所以要想训练的时候就做稀疏化,就要用一些在线的方法
- Poisson Inclusion: 对某一维度特征所来的训练样本,以 的概率接受并更新模型
- Bloom Filter Inclusion: 用 bloom filter 从概率上做某一特征出现 k 次才更新
-
浮点数重新编码
- 特征权重不需要用32bit或64bit的浮点数存储,存储浪费空间
- 16bit encoding,但是要注意处理 rounding 技术对 regret 带来的影响
-
训练若干相似模型
- 对同一份训练数据序列,同时训练多个相似的模型
- 这些模型有各自独享的一些特征,也有一些共享的特征
- 有的特征维度可以是各个模型独享的,可以用同样的数据训练
-
模型共享
- 多个模型公用一个特征存储(例如放到 redis 中),各个模型都更新这个共有的特征结构
- 对于某一个模型,对于其所训练的特征向量的某一维,直接计算一个迭代结果并与旧值做一个平均
-
使用正负样本的数目来计算梯度的和
-
二次抽样
在实际中,CTR远小于50%,所以正样本更加有价值。通过对训练数据集进行二次抽样,可以大大减小训练数据集的大小。可以正样本全部采,负样本使用一个比例 r 采样。但是直接在这种采样上进行训练,会导致比较大的预测偏差,因此可以对样本再乘一个权重。权重直接乘到损失函数上面,从而梯度也会乘以这个权重,先采样减少负样本数目,在训练的时候再用权重弥补负样本。
-
Keras 简介
Java NIO
Channel
既可以从通道中读取数据,又可以写数据到通道。
通道可以异步地读写。
通道中的数据总是要先读到一个Buffer,或者总是要从一个Buffer中写入。
- FileChannel
- DatagramChannel
- SocketChannel
- ServerSocketChannel
Buffer
缓冲区本质上是一块可以写入数据,然后可以从中读取数据的内存。这块内存被包装成NIO Buffer对象,并提供了一组方法,用来方便的访问该块内存。
基本用法
- 写入数据到Buffer
- 调用flip()方法
- 从Buffer中读取数据
- 调用clear()方法或者compact()方法
capacity,position, limit
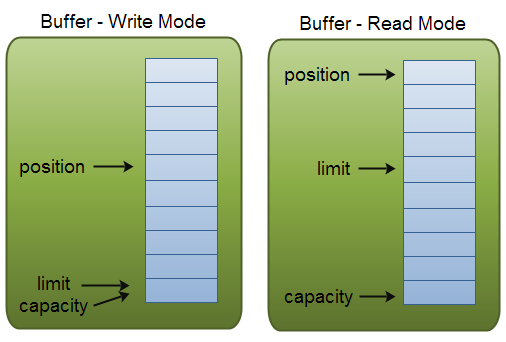
类型
- ByteBuffer
- MappedByteBuffer
- CharBuffer
- DoubleBuffer
- FloatBuffer
- IntBuffer
- LongBuffer
- ShortBuffer
Selector
Selector(选择器)是Java NIO中能够检测一到多个NIO通道,并能够知晓通道是否为诸如读写事件做好准备的组件。这样,一个单独的线程可以管理多个channel,从而管理多个网络连接。
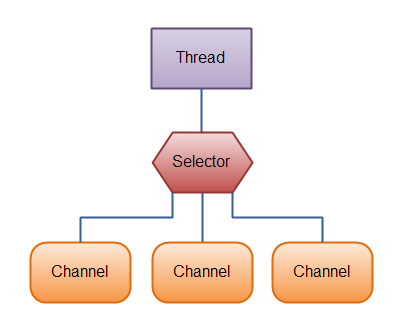
事件类型
| 事件 | SelectionKey常量 | SelectionKey方法 |
|---|---|---|
| Connect | SelectionKey.OP_CONNECT | isConnectable() |
| Accept | SelectionKey.OP_ACCEPT | isAcceptable() |
| Read | SelectionKey.OP_READ | isReadable() |
| Write | SelectionKey.OP_WRITE | isWritable() |
SelectionKey.interestOps()
SelectionKey.readyOps()
int select()
int select(long timeout)
int selectNow()
Set selectedKeys = selector.selectedKeys();
SelectionKey.wakeUp()
Netty 简介
Netty是一个高性能、异步事件驱动的NIO框架,它提供了对TCP、UDP和文件传输的支持,作为一个异步NIO框架,Netty的所有IO操作都是异步非阻塞的,通过Future-Listener机制,用户可以方便的主动获取或者通过通知机制获得IO操作结果。
Major Classes
- Channel
- EventLoop
- ChannelFuture
- ChannelPipeline
- ChannelHandler
- Encoder, Decoder
MessageToMessageDecoder MessageToMessageEncoder ByteToMessageDecoder MessageToByteEncoder MessageToMessageCodec
Transports
|Name |Package | |——–|—————————| |NIO |io.netty.channel.socket.nio| |Epoll |io.netty.channel.epoll | |OIO |io.netty.channel.socket.oio| |Local |io.netty.channel.local | |Embedded|io.netty.channel.embedded |

